Building Business Systems with DSLs for NGINX & OpenResty¶
~ 来自春哥的分享
背景¶
- 5年前也听录了一次 春哥的分享:由Lua 粘合的Nginx生态环境
- 然后, 神奇的引发了各种后来的然后
- 去年, 在 NGINX 大会上, 春哥才真正讲出了10年前设计 OpenResty 前身时内心的宏大构想
- 所以, 值得认真 review 一下:
TL;DR¶

nginx.conf 2016 春哥进行的是压轴分享,对于在主厅面对千人的演讲, 他表示了虚伪的不好意思.

OpenResty 项目发起自10年前,现在已经有完备的团队专门进行维护和开发, twitter 官方帐号是: @OpenResty
推荐关注

OpenResty 在 NGINX 内嵌了 LuaJIT 环境,
得以支持丰富的 Lua 库,结合 NGINX 原生的非阻塞机制,
支持我们可以快速的完成复杂的 web 应用系统,
当前 lus-resty-* 库已经支持非常多领域功能,比如说:
- 各种数据库客户端: MySQL/Pg/MongoDB/RabbitMQ/..
- 各种 upstreams 的健康检验
是的, OpenResty 是成长非常迅猛的社区
OpenResty 不仅仅将 LuaJIT 嵌入到 NGINX ,
感谢 Lus 的 co-routines 特性,
我们还创造了独有的特性,比如说:
- light threads
- timers
OR 的世界观¶
OpenResty 的世界观是 全包容 的,
不排斥其它任何技术, 事实上 resty 用户来自从 JAVA 到 Go 各种技术人群.
NGINX 可以在后端到客户端之间作很多有趣的事儿, 所以, 在 OpenResty 帮助下, 可以很好的完成混合解决, 能和旧系统无缝衔接.

OpenResty 的目标是:
- 简洁
- 轻便
- 快速
- 灵活
认真研究 Lua 后, 我们发现这真是个神奇的恩物, 不仅小而且快,更加灵活,支撑复杂的大型系统也没有问题.
总之这是个设计务实,发展良好,基础稳定的好语言, OpenResty 将 Lua 和 NGINX 深度结合, 倍增了双方的实力.

OpenResty 的 I/O 模式是 无阻塞异步,
虽然 异步 在现实世界中无处不在,
但是,人类的头脑只习惯同步,
当然,俺也反感回调

所以,我们设计了 纤程和信号 来模拟并发, 而实际上只有一个唯一的系统线程.
并发明了: 'Cosockets' ~ 肯接字 (哈N 年前就想翻译了, 现在才有好想法儿)
类似 BSD/Lua 套接字的容器, 支持我们象写 PHP 代码一样写同步表述, 但实际运行是完全异步的.
(是也乎:
golang 其实也借鉴了我们这一设计 )
我们也重新定义了 计时器和睡眠原语, 将异步和下游任务在 NGINX 中完备的分离了, 使用起来就象 cron .

同时还发明了 shm ~ 内存分享式字典和队列,
以便支持我们的应用在 NGINX 不同进程间分享数据,
同时又不打破 NGINX 的异步性能.
而且刚刚我们也开始支持 动态SSL握手, 以便支持下游的 HTTPS 事务.
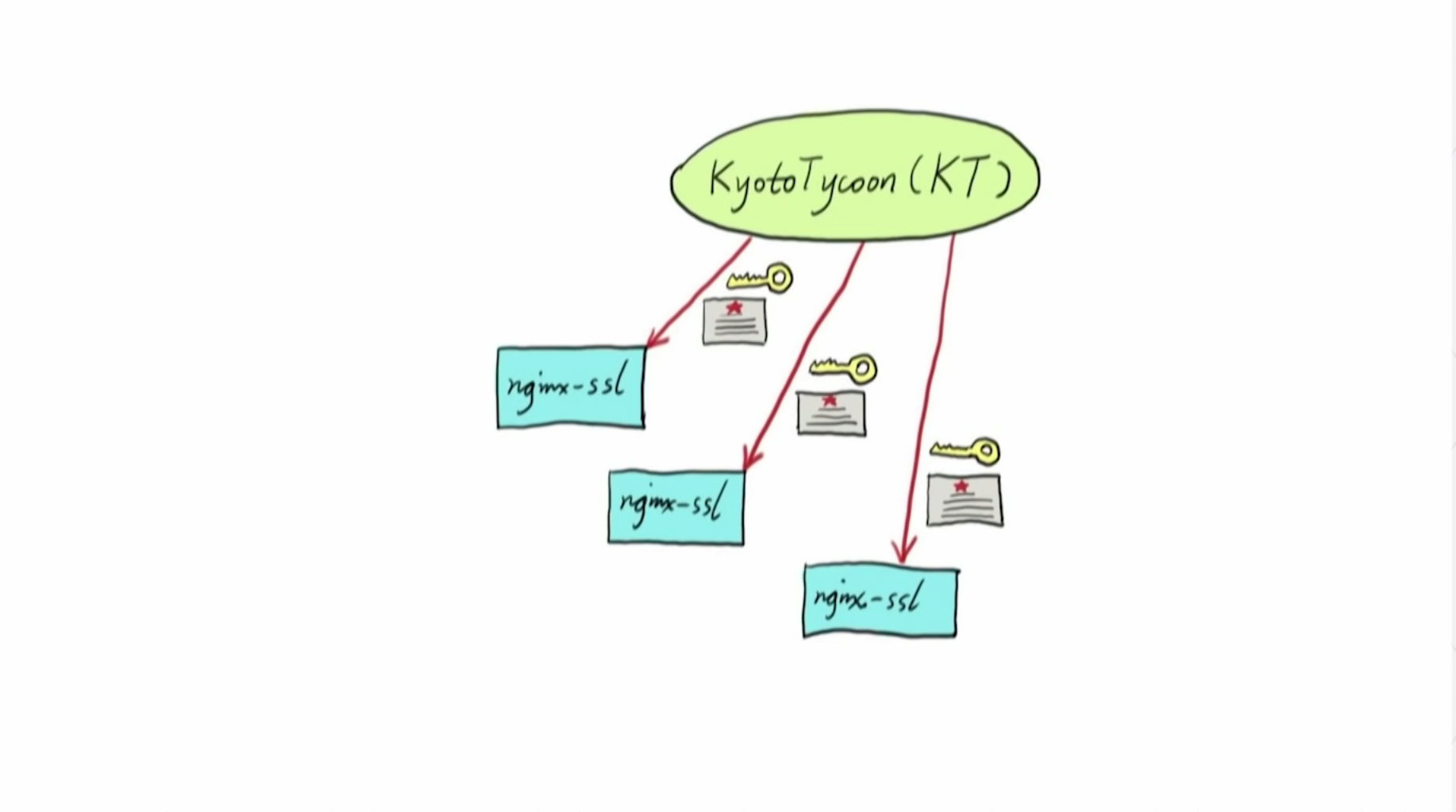
比如在 Cloudflare, 作为CDN 供应商, 有很多客户以及虚拟服务器和边缘服务器构成网络,
要面对的一个主要问题就是: SSL 证书/密钥太多
理论上应该根据实际请求来动态加载对应的证书/密钥, 这样我们就可以同时持有无限量的 SSL 证书/密钥, 感谢本地流量调度, 虽然不可能有单机可以查询所有用户的流量.
进一步的, 在 OpenResty 可以通过 共享内存和工作级缓存中管理 SSL 证书/密钥,
数据 -- 比如: 证书/密钥 -- 当前已支持在 Kyoto Tycoon 中分发, 其它后端,比如说 Redis 或其它分布式存储也当然可以了.

通过 NGINX 中的 Lua 进行动态加载平衡也是能的.

比如这一则配置:
- 几行就可以定义一系列复杂的决策
- 动态, 意味着你可以在该级别上对每个请求灵活应用不同的均衡策略
- 并指定重试策略:
- 比如, 特定请求没有获得响应时
- 可以选择忽略
- 也可以选择请求和请求的位置
- 等等,都在
balancer_by_lua_block中可以声明
- 同时不影响 NGINX 各种标准模块,比如说:
- 以及 NGINX 核心模块,比如: keepalive,连接池等等, 也一样开箱即用

最近我们创建了 ngx_stream_lua_module 模块来替代以往的 ngx_ HTTP_lua_ module
通过 NGINX 核心子系统,来支持实现通用的 TCP/UDP 服务,
实际上 OpenResty® - Official Site 本身的 DNS 服务器就由此模块支撑, 还有人拿个模块实现了类似 syslog 的 TCP 守护进程, 来接收远程的大量日志.

多年以来, 我们积累了大量的专用测试工具.
在 Cloudflare, 运营有全球范围的复杂大型网络, 很多问题发生的几率仅仅有 1% 或 0.1% 甚至于 0.001%, 几乎难以复现, 必须依赖高级调试工具来完成.
已经开源了很多基于 GDB 以及 SystemTap 的工具:
- GDB 主要调试死锁进程,借助 GDB 以及 dump 工具, Mike Pall 已经修复了10多个隐藏在 JIT 中非常深的积年老问题
- SystemTap 则是非常赞的 RedHat 工程师贡献的动态追踪平台,
- 允许分享分析运行时系统,
- 从 内核到 NGINX 整个儿软件桟以及用户的 Lua 业务脚本,
- 都能在对生产系统微小影响下快速分析出来,
- 甚至于不用关闭防火墙
- 可以直接进行线上活体分析
- <-- 这才是未来系统开发的应该姿势
(是也乎:
嗯哼? LISP 构造的系统, 从一开始就这样的哪?! )
OR 的应用场景¶
随着近几个月, 我们发布的重要功能, OpenResty 已在真实客户单主机上支持住了 200万 级别的并发请求,
已经有客户在生产环境中部署了这种级别的推送系统.

另外一个常见领域是接口和微服务,
很多人使用 OpenResty 构建这类服务,比如: Mashape's Kong平台, 以及 Adobe's API Gateway
此外, 一些美国银行使用 OpenResty 来管理路由器流量,
同时, 一些更大的中国互联网公司, 在用 OpenResty 构建实时股票信息服务, 这些接口是其中流量最大的,
还有用来发布实时天气信息接口的...
等等吧, OpenResty 的应用可能是无限的.

另外一个 OpenResty 的应用场景是 web 网关, 很多 CDN 厂商都在这样使用.
我们还知道有人用 OpenResty 来管理通用 TCP/UDP 流量,
Lua 可以支持你的网关在运行中得以变化, 基于互联网的动态性, CDN 厂商必须灵活的应对客户的不同需求, 而客户的需求越来越复杂化.
甚至于人们在期待可以包含业务逻辑,比如常见的想动态修订配置文件,来支持软件更新, 等等出于实际需求的要求.
选择 Lua 令一切变的可能, 因为 JIT (即时编译)的机制, 可以随时根据变更的配置生成新的规则, 并根据不同的请求进行对应的流量优化...
NGINX 原先就支持基于 HUP信号 的配置重加载, 但是, 这对于厂商而言成本太高, 因为无法精确的退出相应请求来重启.
另外, 缓存也是个大问题:
- 有时一个客户的缓存非常冷
- 但是,又不能为了释放这部分数据而重启整个儿缓存
- 这对其它用户来说太惨了...

OpenResty 原先设计目标是支持完备的web 应用, 第一个案例是网站, 所以,有了 openrety.org
如今有越来越多的传统网站,在用 OpenResty 从头开始构建
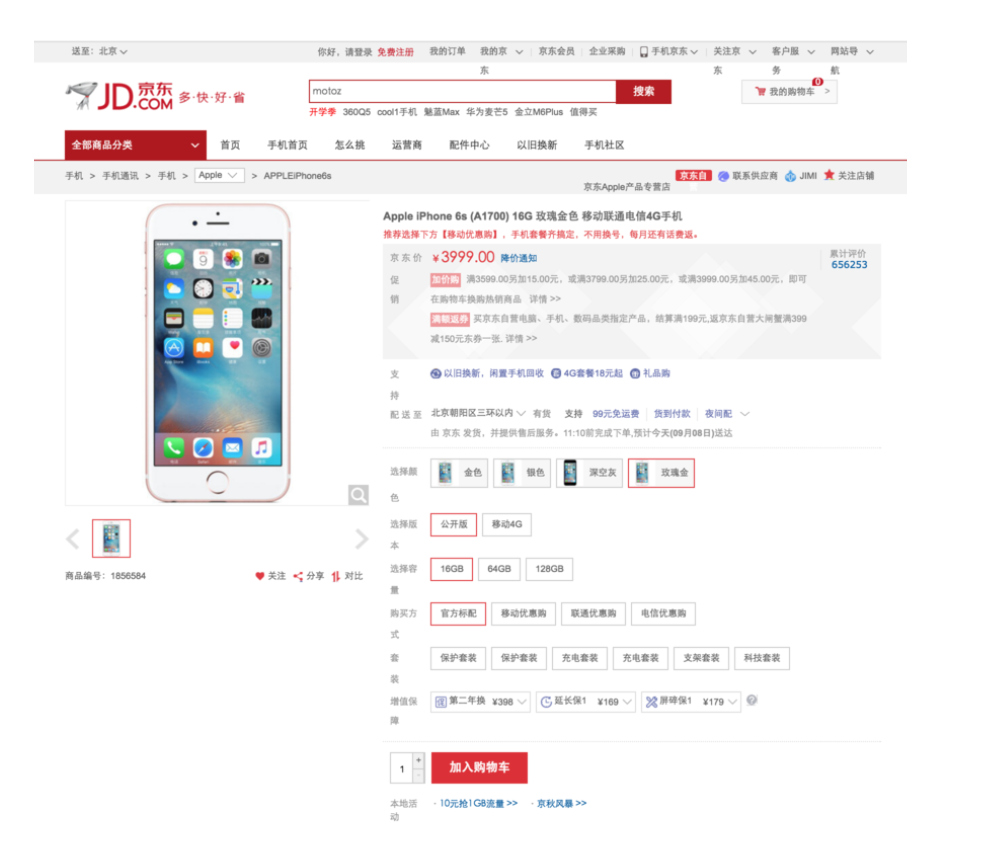
例如 京东网, 中国最大的 B2C 电子商务服务平台之一. 在各种营销日, 他们必须面对海量的请求, 类似美国的黑色星期五, 在中国则是 11.11
(是也乎:
问题在中国的光棍节营销流量, 是黑色日期五的几个数量级哪!!!
毕竟, 美国的打折多数是线下的...
)
最早他们使用 Starnet 技术, 经常崩溃, 后来迁移到 JAVA 技术桟, 全然崩溃.
最终迁移到 OpenResty ,虽然后端依然是 JAVA, 但是迎接所有流量的全部是 OpenResty 了, 从此再也没有崩溃过.
现在他们使用 OpenResty 来生成复杂的网页.
比如这个截屏,是 iPhone 的详细产品信息页, 类似页面吸引了主要的流量, 基于 OpenResty 的模板库来生成动态页面, 这是个非常长的页面,只截取了顶部,
他们内部维护了一个非常庞大的模板库, 并用 Redis 来缓存数据 ,以免流量直接击中后端的 JAVA 服务,
春哥曾经询问 JD, 是否需要优化, 他们回答,速度已经足够快, 不用了,谢谢...
(是也乎:
这可能是由于性能太好而丢失定制服务的最好案例, MySQL 只能表示 23333 了... )
我们自己则重构了官方网站, 整个网站使用 Lua 在 OpenResty 上重写而成,
使用 PorstgreSQL 作为后端数据存储, 通过 OpenResty 直接和数据库交互,
通过 NGINX 的异步非阻塞进程来处理 IO, 非常快速并便宜,
基于 Pg 内置的全文搜索而支持了网站的内部搜索功能.
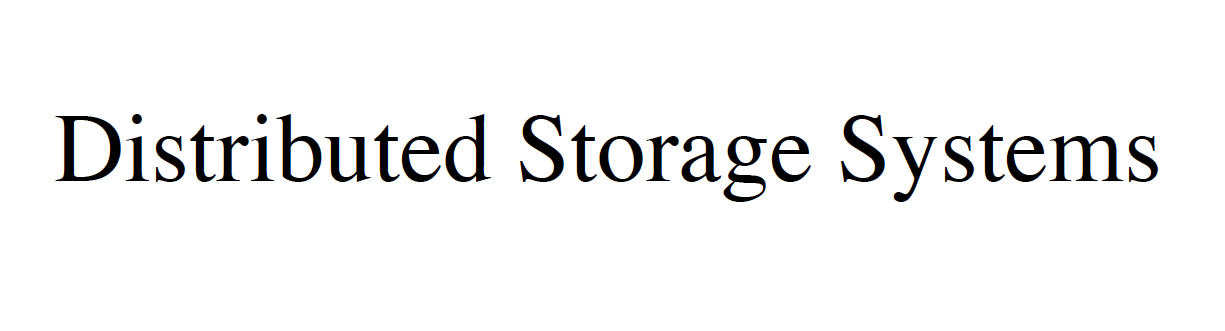
这是令春哥自己都惊讶的领域:
- 作为中国最大的网站之一 sina.com
- 发布有类似 Jawbox 的网络存储产品
- 他们不仅用 OpenResty 来构建前端
- 而且还用在后台直接处理文件 I/O
- 对于这种操作他们非常自得
- 也非常自豪的成为 OpenReaty 核心组件贡献方之一

Datanet 则是另外一个类似的项目, 虽然没开源, 但是,作者在努力中,
创始人是 Russell Sullivan, 在 twitter 是 @jaksprats
正在基于 OpenResty 构建一个分布式数据网络, 推荐大家去直接嗯哼...

CRDT ~ 无冲突数据复制类型,
简单的说, 这是全新的复杂理论,
涉及复杂的算法和论文, 还在折腾中...
基本上象个 半p2p 网络,
每个节点都可以有状态,通过 类似 p2p 的机制完成自动同步,
为什么叫 半p2p 网络,因为这其中必须有某种中心,
可以是大型数据中心,
以便支持暂时下线的节点, 重新上线时,快速发现差异完成同步....
是的, 机制很复杂要说明白得额外2小时...
(是也乎:
不就是不完备的区块链网络嘛... )
大事儿: sregex¶
sregex <-- 春哥一直在造的轮那 ~ 正则表达式引擎,
当然是为了真实的业务需求
(是也乎:
但是,这是阻止不了从头造轮子的快感的...嗯哼! )
本质上她必须可以支撑处理流式数据, 毕竟 web 服务器要处理的数据理论上是无限大的.
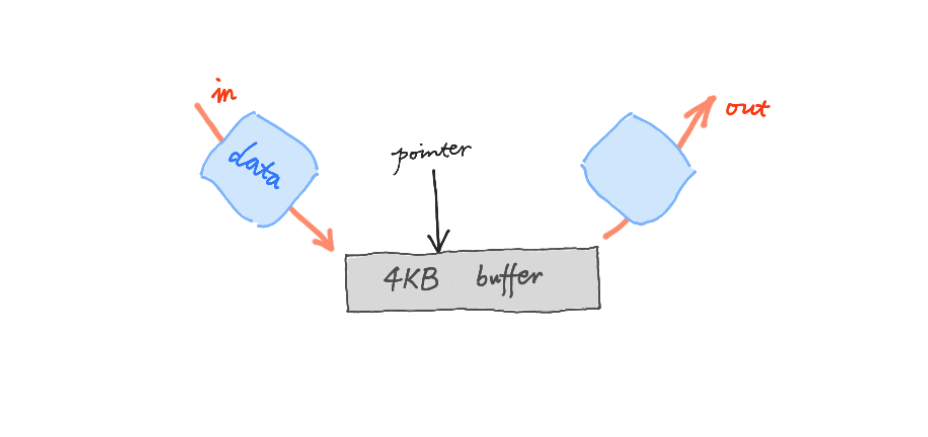
关键问题是高速处理缓冲区块:
- 缓冲总是混沌的
- 通常很小,比如 4k
- 数据一进入, 就必须完成处理,得到我们需要的,并作出决定:
- 丢弃
- 或是通过
- 而且是单向流水线
- 一但数据块被处理
- 立即将被下一组填充
- 这一构想很得趣, 但是,不简单
- 算法非常困难, 传统的都不行...
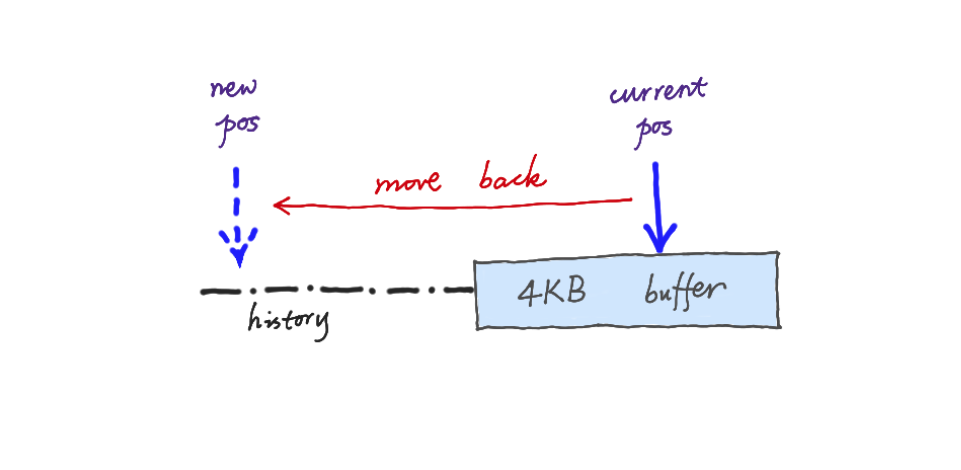
回溯算法在主流正则表达式引擎中很流行,
基本上, 当你找不到匹配时,就将指针逈后移动再重试.
PCRE 以及其它很多引擎都是基于这一算法的, 但是,包含了很多问题,不仅仅是固定缓冲区的要求.
还可能引发非常昂贵的系统资源浪费,
这种现象我们定义为: 病理行为
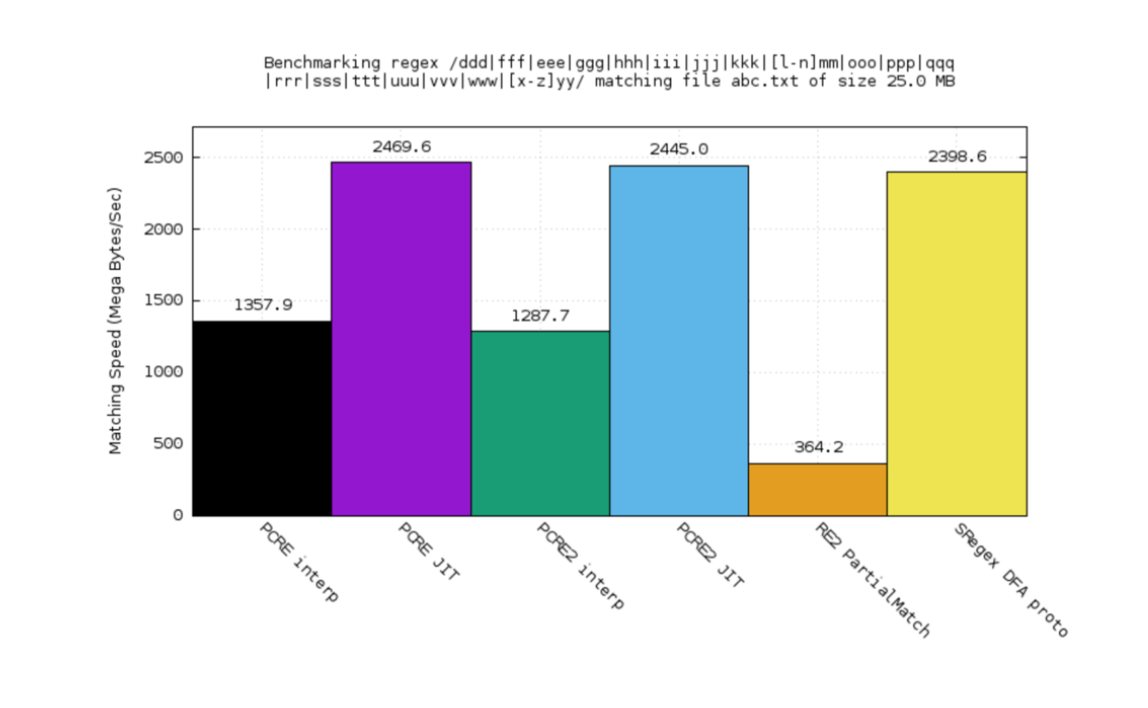
春哥构建了 DFA (确定性有限自动机), 当前性能尚可, 如图中所示:
- 橙色->Google RE2
- 紫色->PCRE JIT
- 黑色->PCRE
- 绿色->PCRE2解释器
- 蓝色->PCRE2 JIT
- 黄色->sregex DFA 原型
PCRE 是 C 实现的 Perl 兼容正则表达库,性能口碑很好
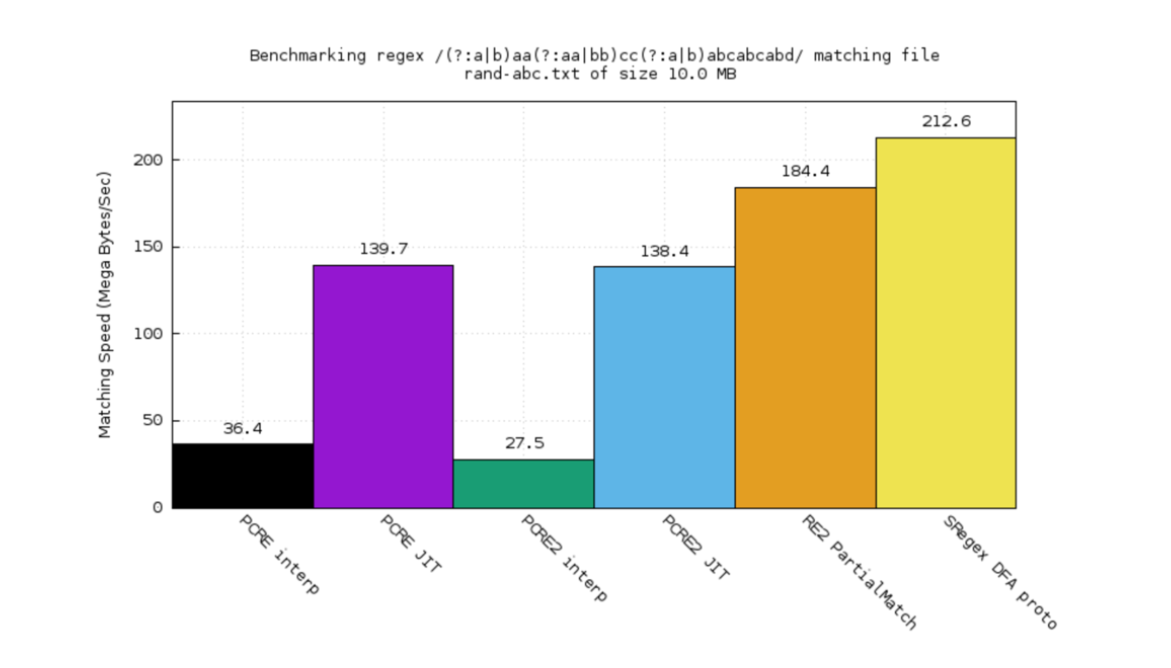
在这个有点儿复杂的测试案例中:
- RE2 比 PCRE 好
- 甚至于比解释器版本还好
- 但是, sregex DFA 原型 依然更好点儿
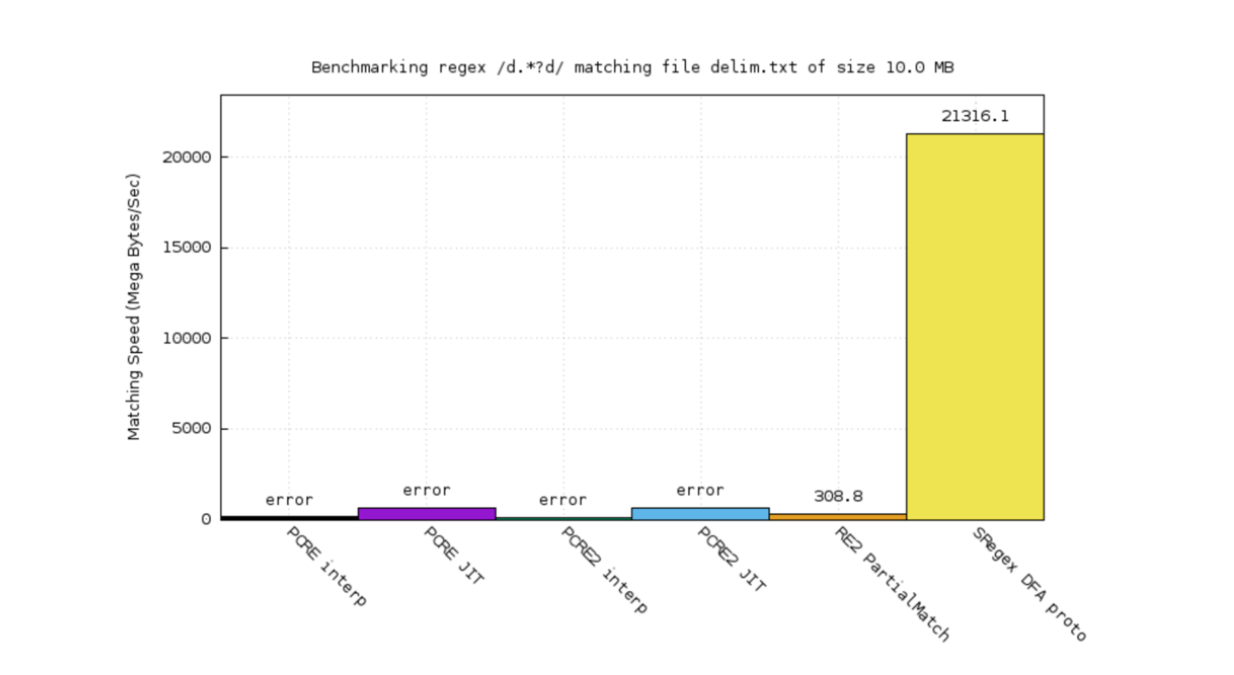
而在 /d.*?d/ 这一简单案例测试中:
- 我们的原型获得了极大的优势
- 因为 DFA 可以进行智能优化
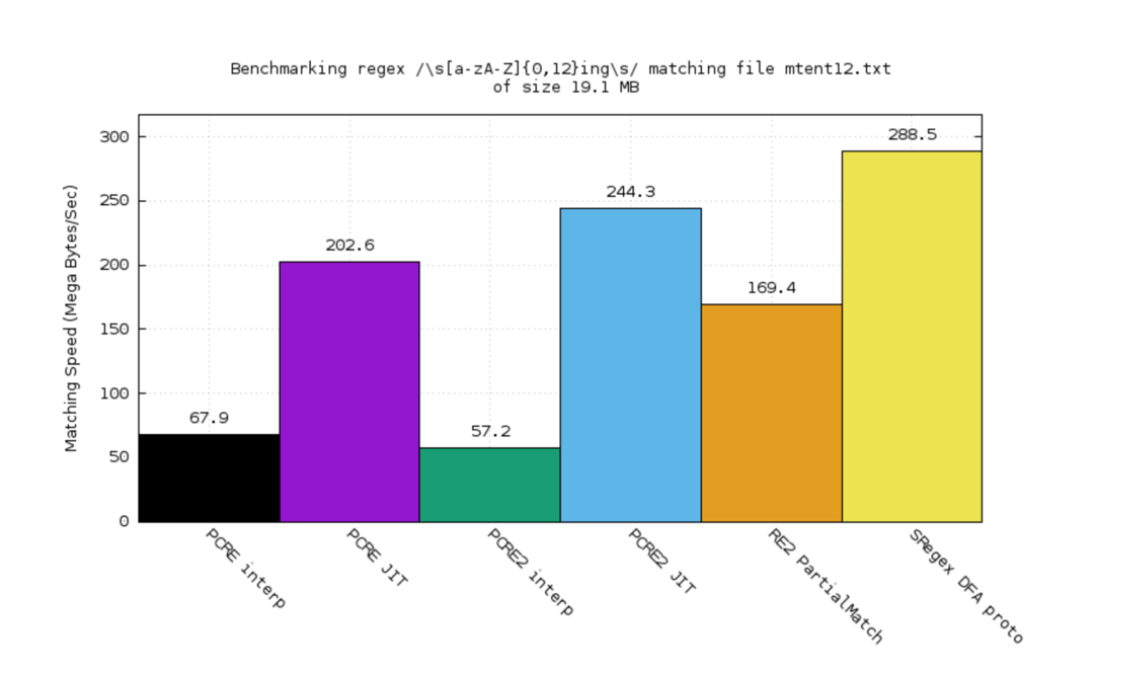
在 PCRE 提供的性能测试案例集中, 我们(黄色)领先一些
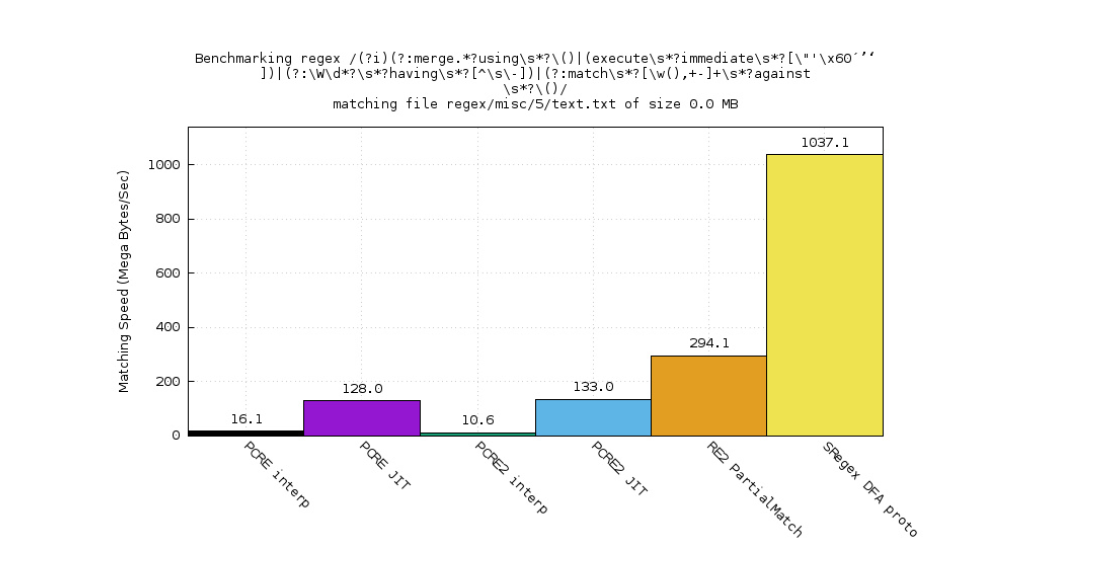
这一正则表达式案例是从 ModSecurity 的核心规则中抽取的, 应用在 WAF(web 应用防火墙)过滤核心中.
- 回溯引擎浪费了大量 CPU 资源,因为在反复回溯
- sregex DFA 原型则相反, 非常快
sregex 将是 OpenResty 接下来的重心!
- 当前还不是产品状态, 只是个快速原型
- 春哥用大约2000行 perl 代码实现了一个正则表达式引擎
- 以便生成能被 clang/GCC 编译的 C 代码
- 完成这些,只是为了印证设想
我们认为:
自己的 JIT 引擎比 Clang/GCC 更好,因为优化器更通用
自己的 JIT 引擎比 Clang/GCC 更好,因为优化器更通用
自己的 JIT 引擎比 Clang/GCC 更好,因为优化器更通用
(好吧, 重要的事儿得说三次)
DSL实验: LZSQL¶

回到主题: 建立在 OpenResty 上的 DSL
先分享了一系列 OpenResty 的新功能,
但是,更重要的是, 春哥认为:
- OpenResty 可以视作 VM(虚拟机)
- 就象 JVM
- 可以更加强大, 更加面向 web
这个实验其实是7~8年前完成的,不算新鲜,但是,实验是值得回味的.
那时春哥供职 taobao, 是 alibaba 集团子公司, 是中国最大的 B2C 平台, 当时在数据分析部门, 客户是 taobao 的商家, 类似 eBay 的商家就是卖家一样.
客户需要一个流量分析工具, 来统计店面的流量,和广告部署/销售间的影响力关系, 这是个非常大的产品.
(是也乎:
为什么大? 因为要分析的数据量,相当于好几个 twitter 的数据量.... )
这是产品首页
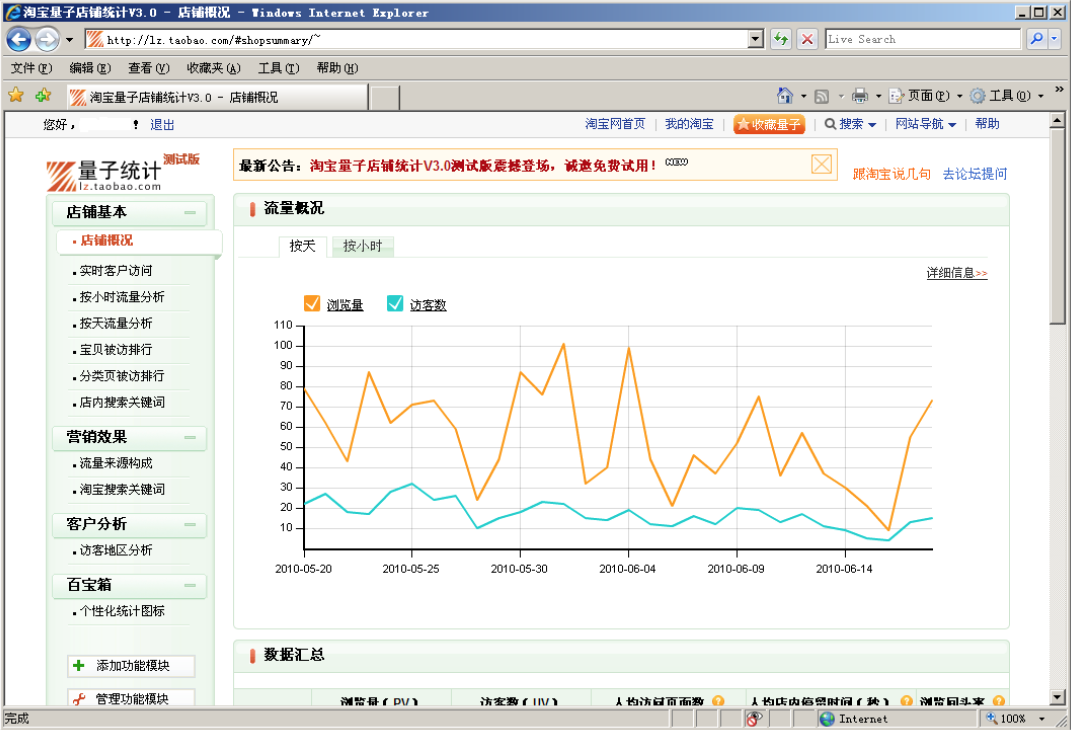
给出了类似 google 分析样漂亮的图表, 所不同的是有更多数据报告.
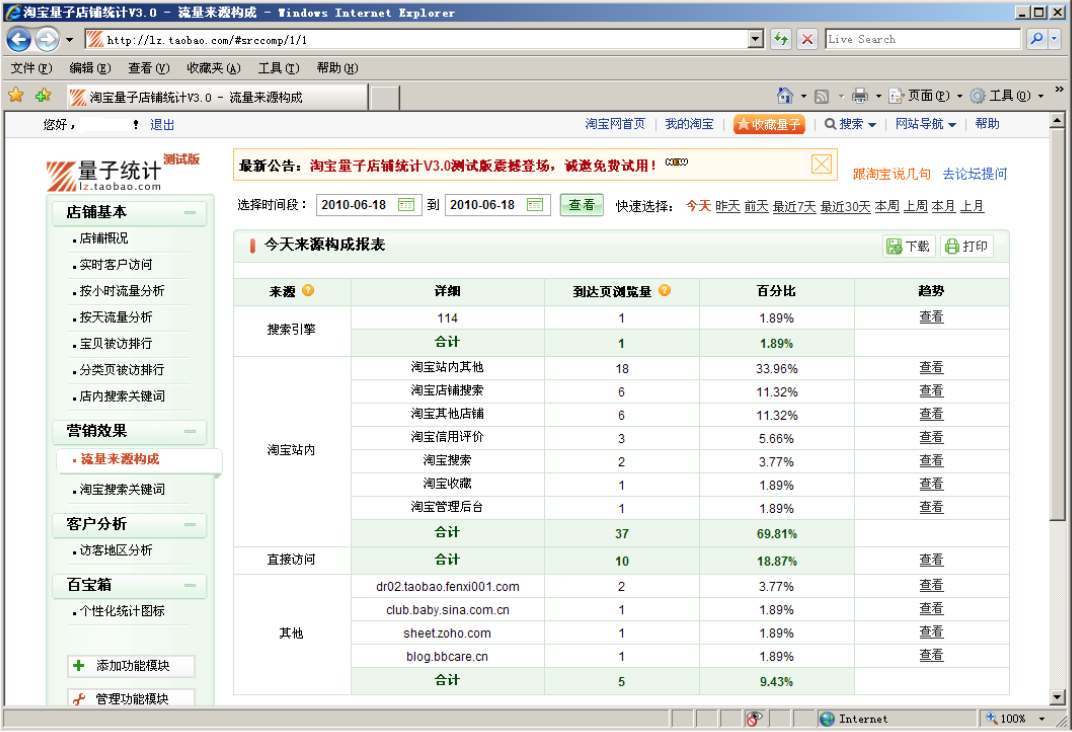
由于 yaobao 的体量,数据量很大, 非常的大
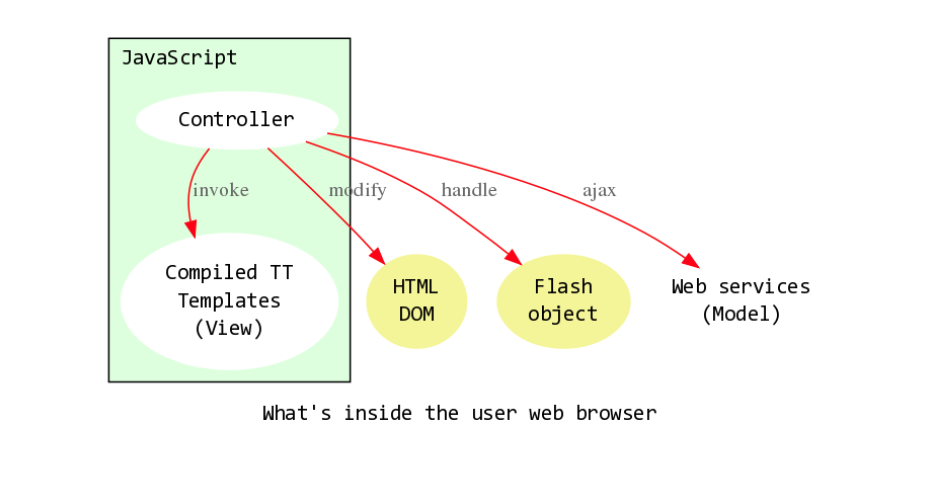
当时春哥 放胆在客户端进行各种尝试,8年前:
- 整个儿应用逻辑已经全部在前端了
- 类似 gmail ,完全由一组运行在网页中的脚本构建
- 还引入了客户端模板:
- 构建了一个能从模板生成 JS 代码的引擎
- 另外也提供了 web 服务来驱动客户端应用
- 总之, web 服务是关键,是唯一运行在服务器上的东西
- 将 JSON 发送给客户端
- JS 用编译后的模板生成页面区域
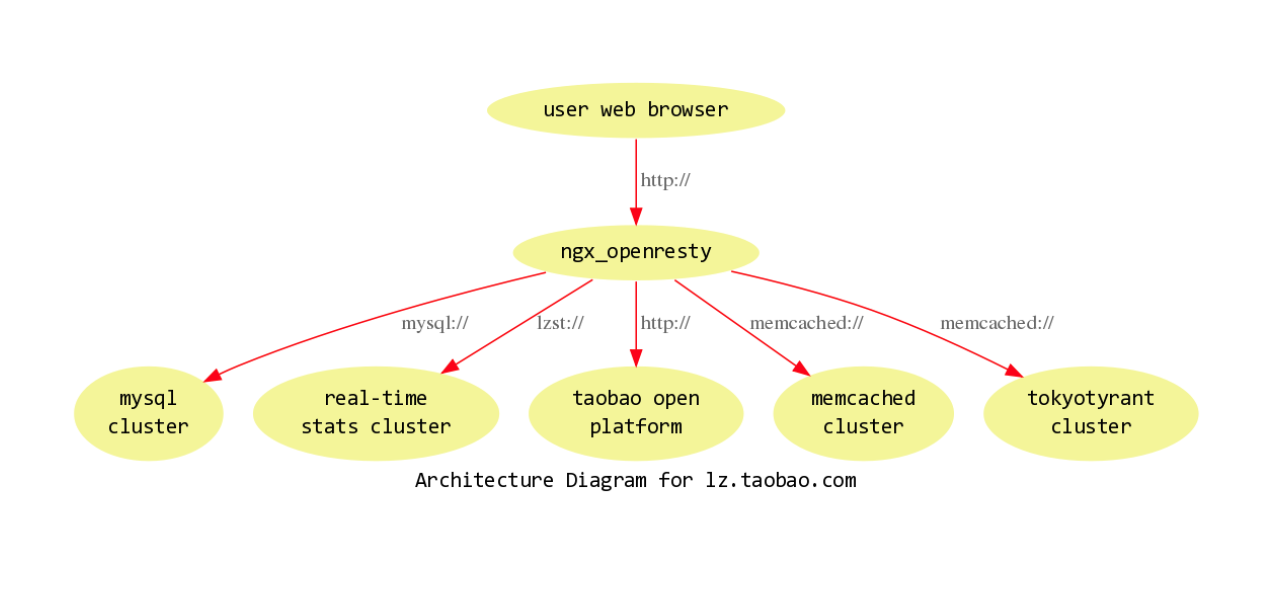
量子统计整体架构如上:
- OpenResty 位于后端和浏览器之间
- 后端是 MySQL 集群,因为数据量大, 光卷就有超过1亿个
- 另外还有实时统计集群作支撑
- 同时还作为一个开放平台发布 JSON 的 API
- 以及 Memcached 和 Tokyo Tyrant 集群来管理其它元数据
- 但是, 相比其它系统要简洁的多,只用 PHP 来运行
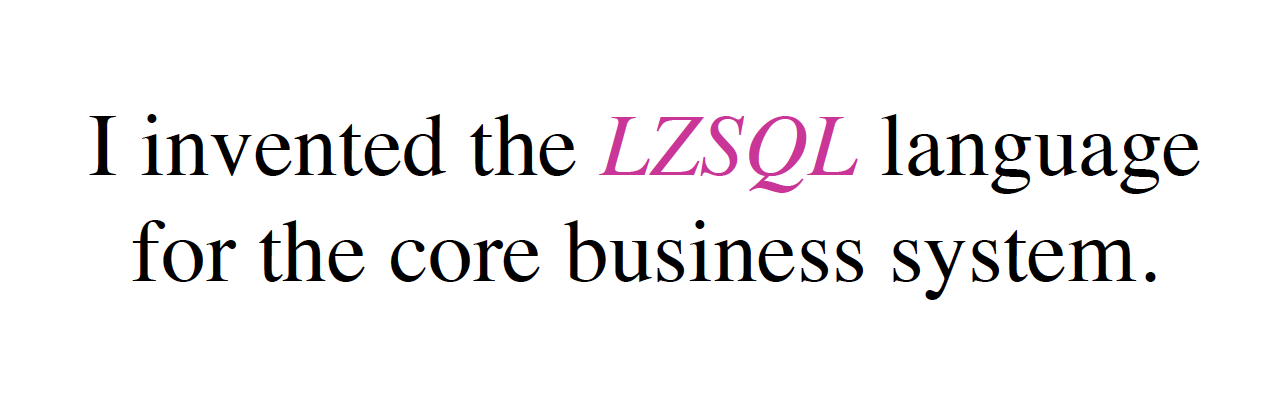
春哥很快意识到关键问题:
- 没有足够的人力来支撑开发
- 整个儿团队只有两个实习生
- 但是, 不得不将原先 PHP 编写的整个儿数据分析产品迁移到 OpenResty 平台
- 即使迫使实习生拼命写 Lua 代码,但是,面对复杂到狂乱的业务逻辑,这是个不可能的任务
春哥用了一个晚上思考, 决定:
- 基于对数据分析核心模型/模式的理解
- 构建自己的 DSL
- 以便用更加自然的形式来描述业务
毕竟: 什么是编程?
- 本质上是和机器对话
- 令机器理解我们的意图
- 从而快速/便宜/可靠的完成业务
所以, 编程的关键是:
提高同机器对话的效率
那么, 如果你能用两个词或是一个句子来表达一个想法, 为毛要使用十多行代码? 那也忒自虐了!
所以, 春哥不喜欢 JAVA, 因为要输入的代码太多了, Lua 也不是个好形式, 以及其它现有的所有命令式通用开发语言
所以有了第一个 DSL: LZSQL
- 基于SQL 的形式, 快速传达想法给系统
- 为什么选择 SQL ?
- 因为数据分析产品本质上是基于关系型数据模型的
- 无论是否使用 SQL 数据库
- 我们可以在 SQL 中定义变量和用户变量, 作为第一公民
- SQL 可以在一些 MySQL 后端运行
- 也可以在 NGINX 中运行
- 因为实现了包含 SQL 引擎的内存数据库
- 只有100行左右的 Lua 代码
- 运行良好
- 复杂性来源是因为数据不得不来自很多不同的 MySQL 数据库
- 然后在内存中重新关联, 并组合成最终结果发送到客户端
- 这其中涉及很多棘手的问题:
- 必须能分解 SQL 到不同节点上运行
- 同时还能自动优化 SQL 查询
- ~ MySQL 自己的优化器通常无法完成海量优化
- 特别是在 OLAP 场景中
- (在线分析过程)
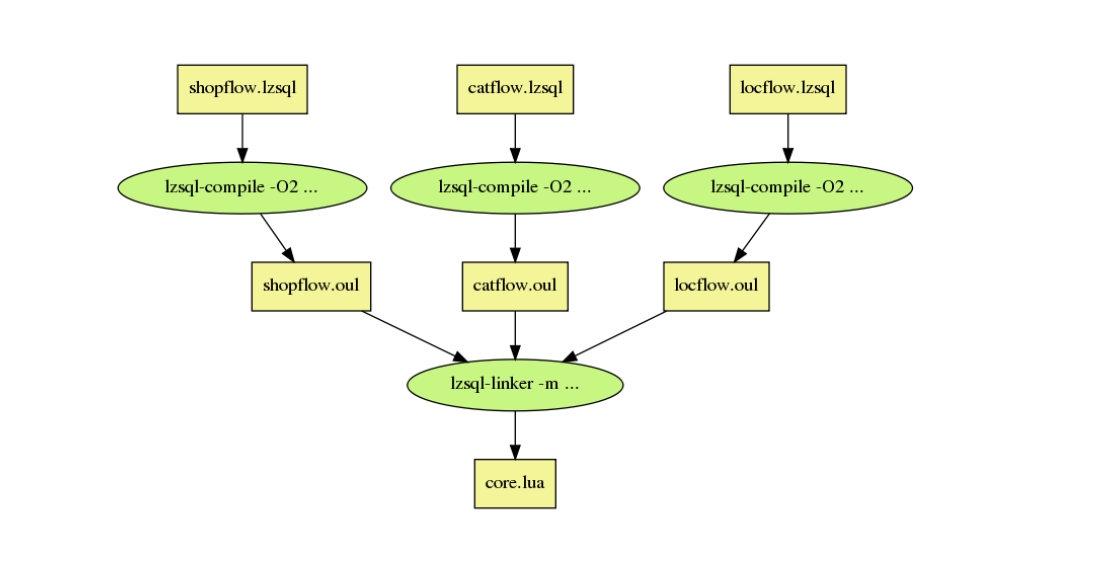
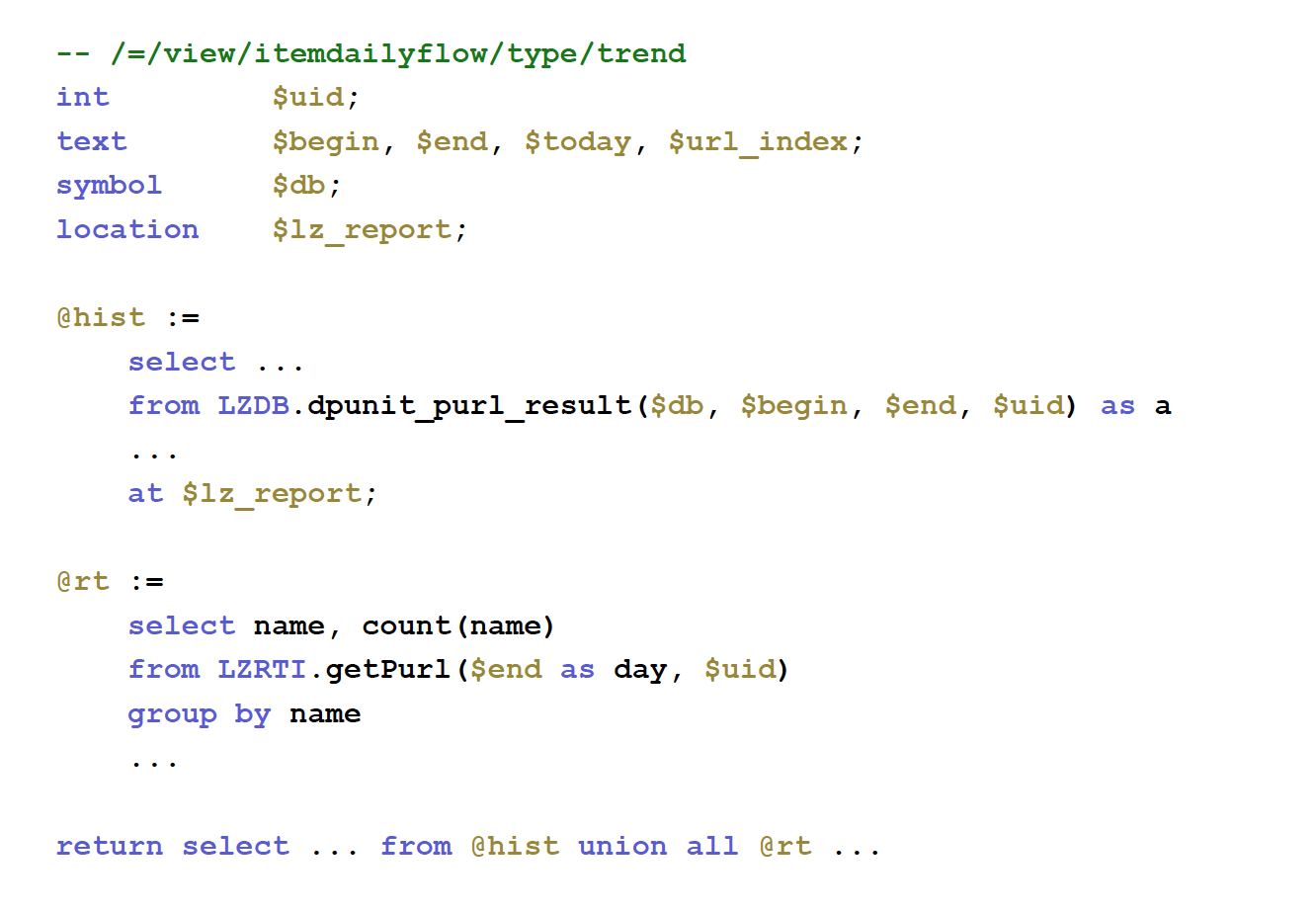
最终, 实际上我们用 LZSQL 来记述业务逻辑, 用编译器生成 Lua 代码, 在线发布 Lua 代码并运行, 而线上不再需要编译器.
这就是 编译 的美妙所在.

当前的, 提供 CLI 工具, 完成 LZSQL 脚本的编译, 链接到最终 Lua 应用程序.
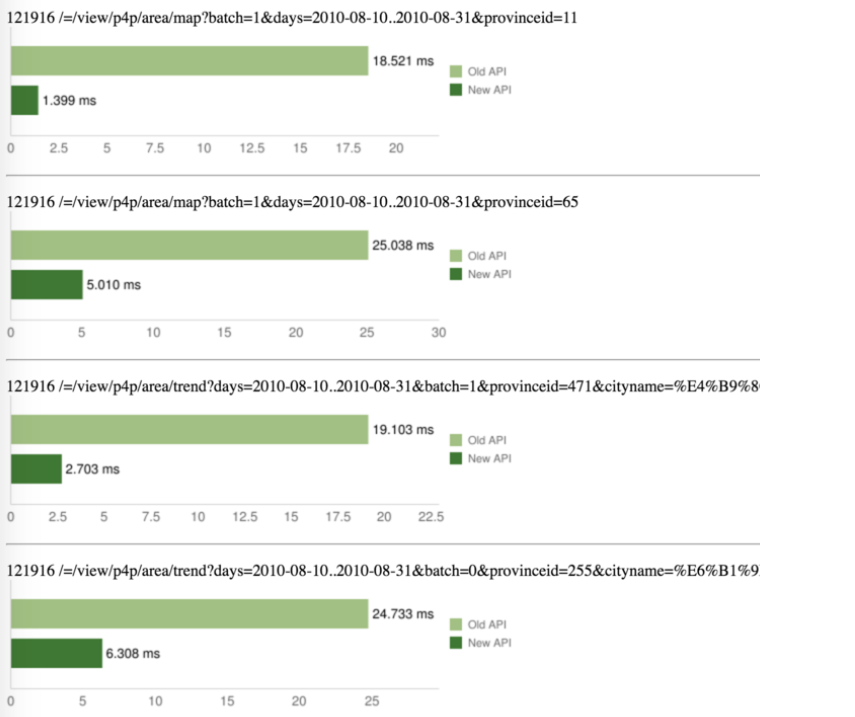
其结果非常赞:
- 因为编译器可以进行很多优化
- 人通常不能, 甚至于不能正确运行
旧业务是 PHP 编写的,新接口由春哥编译器生成 Lua 代码,
- 请求延迟下降超过 90%,
- 甚至于这包含了 MySQL 的延迟,
- 上图是一次完整的 接口 HTTP 延迟对比
值得注意的是, 这时使用的还是标准的 Lua 解释器
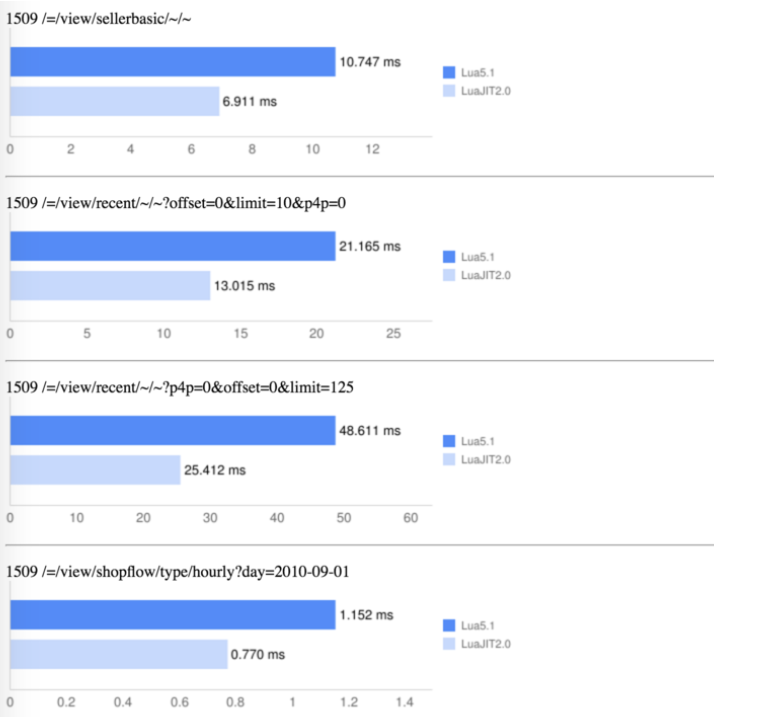
进一步的, 仅仅切换为 LuaJIT , 速度就获得进一步加强
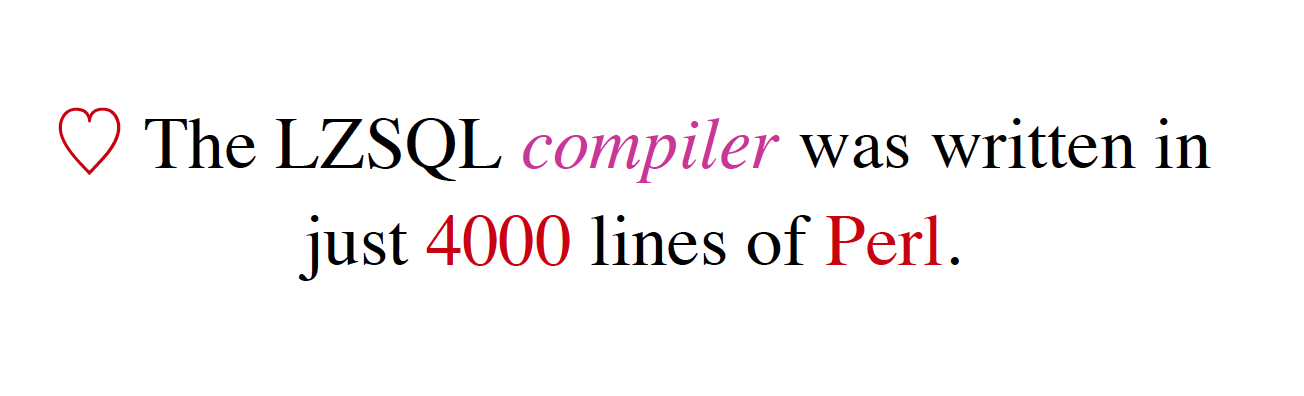
而实际上, LZSQL 编译器,仅仅是 4000行 Perl 代码, 但是,包含了非常复杂的优化和类型检查以及一应上下文相关的分析过程.

而且, 编译器包含了:
- 一个解析自己的解析器
- 一个 AST(抽象语法树)
- 一堆优化器
- 一个代码映射器
- 其实是多种映射器
- 因为 LZSQL 支持多种语言后端
是的, 当时可以生成 Lua 代码, 当然, 也可以生成 C 代码.

是的, 当时后端是一个实时数据库, 提供了非常具体和复杂的线程协议,以至难以人工完成客户端.
但是, 数据库发布有一个完备的wiki 文档:
- 那么为毛不让电脑可以理解文档
- 自动生成一个 NGINX C 模块来调用呢?
于是, 春哥实现了这个想法

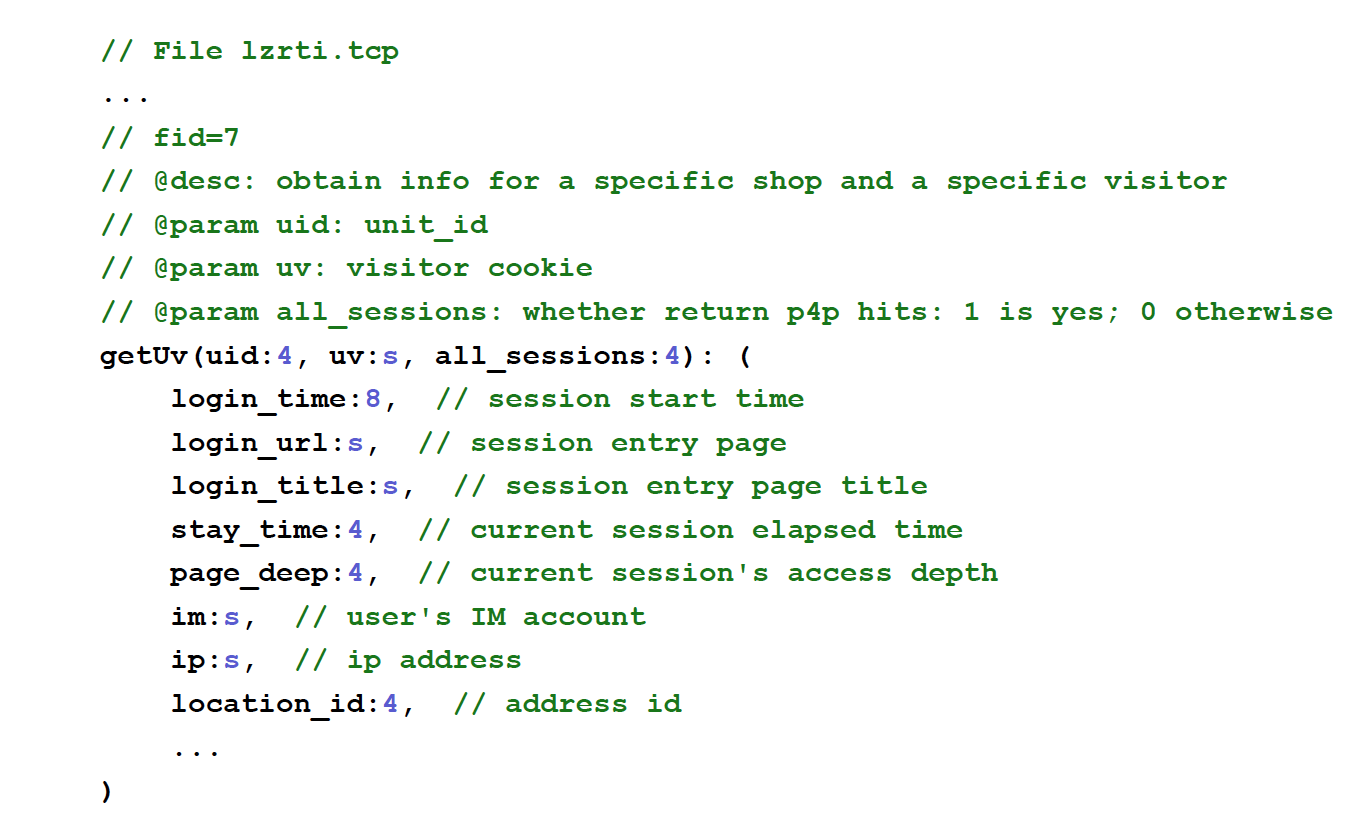
是的, 嘦很小的 DSL 抽象就可以解析 wiki 文档.
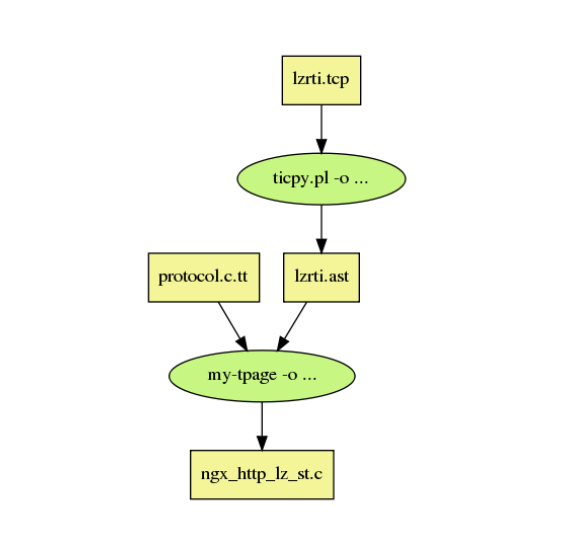
于是, 再再再次用 Perl 快速完成了一个编译器来从文档生成 NGINX C 模块, 可以自由的通过 NGINX 来和数据库交互,
这算 NGINC 的上游模块.

是的, 文档只有300行, 但是生成的 C 模块有12000行代码.

这一案例说明:
- 编程就是和机器沟通
- 如果文档足够完备
- 那么完全可以直接转换给机器
- 从而避免了人工编程的各种糟心事儿
- 这一切指向了一个觉悟:
:
宁愿写程序上编程来生成代码
(是也乎: 也嫑直接写业务代码)

同时我们的测试脚手架也是基于 DSL 的:
Test::Nginx::Socket被所有 OpenResty 工程引用- 以规范的形式来描述测试用例
即使你不会 Perl 也没有关系:
- 嘦按照规范提供描述
- 服务就能理解并进行对应测试
DSL 的爆发¶

幻灯参考: http://search.cpan.org/perldoc?Cheater
接下来的一件大事:
- 对于新产品
- 数据库中还没有真实的业务数据时
- 如何进行测试?
- 我们需要数据来测试 SQL 查询/网页/服务/...
所以, 春哥再再再再次用 Perl 实现了一个类似 SQL 语言的建数据表用的 DSL
就是 Cheater 工具:
- 用正则表达式来指定允许渲染的字段
- 并能指定依赖的外链
- 那么这工具就能生成满足所有约束和要求的随机数据
回到 OpenResty 场景中, 从多年前的实验中可以学到:
- 可以通过设计/实现模式语言来简化开发
- 可以在 OpenResty 中使用 SQL
- 编译器知道在哪儿运行:
- 本地或是远程
- 又或是混合
- 在不同数据库中运行 SQL ,甚至于不一定是关系型数据库

另外, 也发布有 OpenResty View 语言:
- 基于 MVC 模型
- 在 View 层:
- Perl 有 TT2
- Python 有 Jinja2
- 现在有了自己的 DSL 就可以生成客户端 JS 或是服务端 Lua 代码
- 这是 DSL 的优势
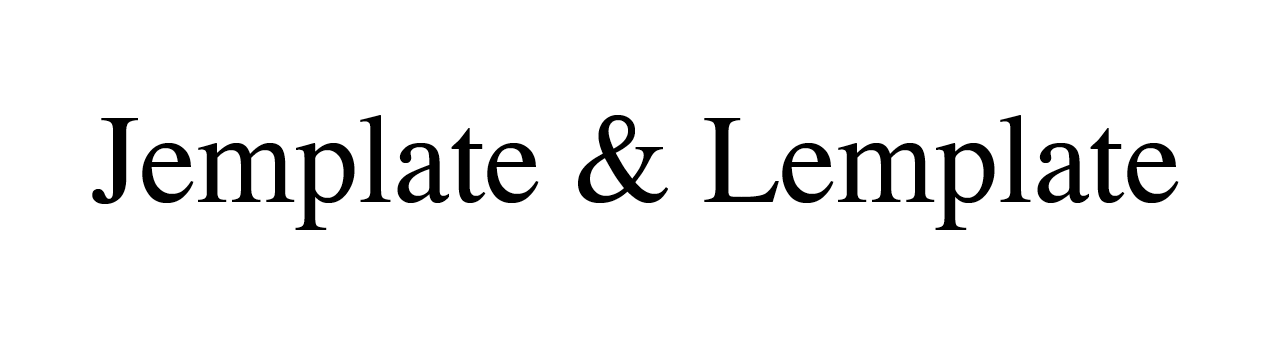
- Jemplate 将 Perl 的 TT2 模板转换为 JS 代码
- Lemplate 则编译成 OpenResty Lua 代码

这又是一件大事儿

看起来是这样的:
- 基于规则的语言
- 你只需要描述一系列规则
- 箭头左侧是谓词, 类似条件
- 箭头右侧是行为, 比如重定向/返回错误码...
- 那些谓词其实是无效的 (不会导致执行具体的行动)
- 编译器进一步优化的话, 就能将机关的谓词合并起来
- 多数 CDN 业务编辑都可以如此表述<--这就是 CDN 市场的本质
不同的商业模式包含共同的内在特性:
- 这是可能的也是可以的
- 比如数据分析业务共同的模式是关系模式
- SQL 语言洽好是这种模式的表述形式
对于 CDN 或是 WAF 型的业务:
- 应该就是规则集的模型
- 理论上是个
前向链专家系统模型
春哥是 AI 的资深粉丝
- 高中时就研究过各种流派的 AI 实现
- 当前机器学习是热点
- 而专家系统是 AI 的分支, 并没有过时
- 比如说:
- 基于 Prolog 的语法解析, 在自然语言研究领域很流行
- 而语义解析, 则多用 CLISP
- 70年代 NASA 就折腾过类似的

OpenResty 也支持组合多个 正则表达式 来执行复杂的过滤:
- 这样,所有替换在 NGNIX 输出过滤器中
- 是缓冲实时完成的
- 所以, 定长缓冲区, 无限数据流处理
- 非常 COOL , 不是嘛?
上图是批量从 C++ 中删除注释的案例
- 你可以稍微修订就能支持 CSS/JS 的注释删除
- 当然的,这是基于 sregex 的

WAF 是热点, 公司已在为 NGINX 推出 ModSecurity 端口,
春哥看来 WAF 本身就可以基于前述控制语言来完成.

ModSecurity 本身作为 DSL 很可怕
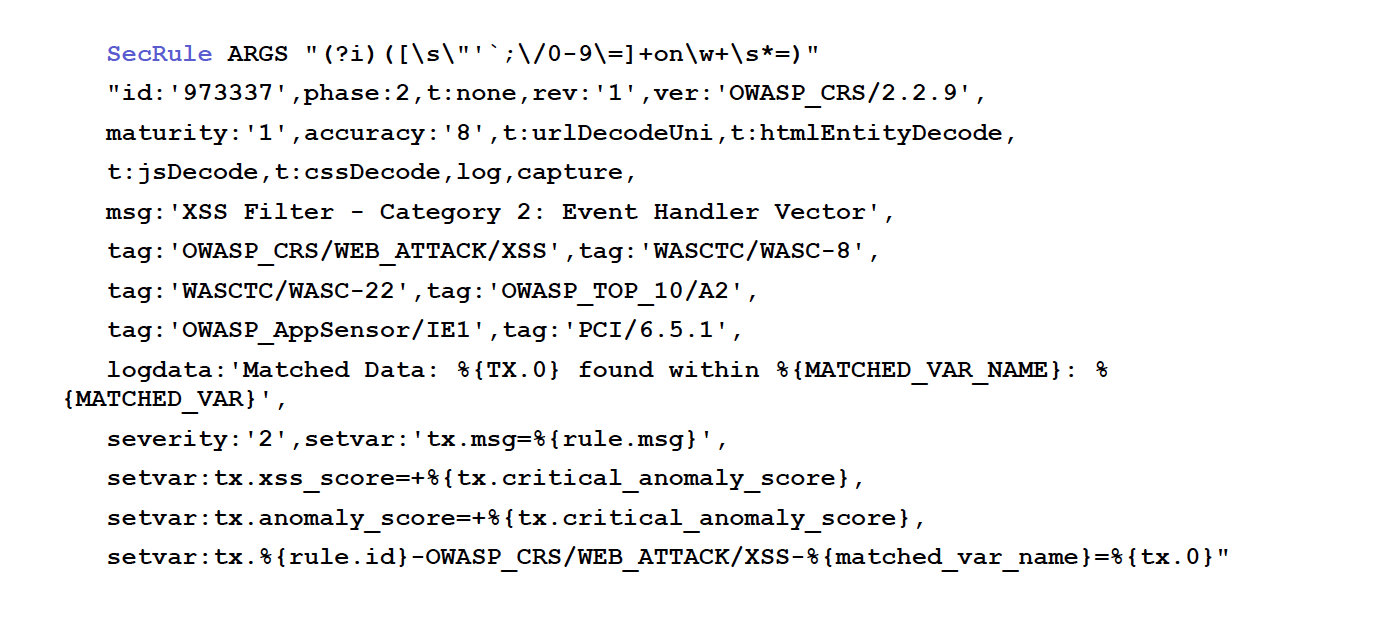
这是 ModSecurity 一个线路的描述
已经复杂到天际了, 而厂商们还发明了各种更加复杂 WAF 语法,
只是为了表述类似 if-else 的逻辑
那么为什么不创建我们这样简洁的 DSL ?

这样的语法就干净很多:
- 也支持短路:如果第一条匹配了,就跳过后续的
- 本质上只是个
if-else不必要进行深度嵌套 - 如果查阅其它 CDN 厂商的 VSL 代码
- 其实就是一堆堆的
if-else - 是的, 很疯狂
- 其实就是一堆堆的
OR 的目标¶

- 模式 ~ 不同种类的商业系统都有内在相似的模型,从而抽象为一个 DSL
- 视图 ~ 已经完成很多种模板语言,都是 DSL
- 控制 ~ 也已经展示了, 通过规则的描述可以简洁的完成 WAF 业务的定义
运动类游戏当然也可以拥有自己的语言, 来描述业务系统.
还能更 COOL 嘛?
我们作为软件行业的专业人士, 讲真, 强迫其它行业用户(如物理/数学/建筑/哲学...)来使用计算机语言, 这本身算是种耻辱吧.
理想情景中, 我们应该支持用户:
- 使用他们熟悉的领域语言
- 自然的描述
- 而机器可以理解并运算
而且, 同时:
- DSL 还包含了大量的自动优化过程
- 毕竟这不是每个程序猿都知道的技巧

当前我们内部已经在使用 Y 语言:
这是全新的能调试多种语言的工具, 类似 GDB, SystemTap, LuaJIT

另外也支持 CoffeeScript :
- 毕竟 CoffeeScript 很受欢迎
- 这种 DSL 可以生成 JS
- 现在我们可以从 CoffeeScript 生成 OpenResty Lua 代码

我们也有元DSL:
- 用来生成其它所有 DSL 的 DSL
- 包含 元DSL 本身
我们还有创建编译器的 DSL, 能生成:
- DSL 编译器
- DSL 优化器
Perl 一直是 春哥 的第一序列武器, 但是,并一定是最好的, 最终可能为构建编译创建专用 DSL

我们可以在业务描述和业务实现间进行清晰的隔离.
这意味着我们可以一夜之间, 完成业务系统实现技术桟的切换,而不用触动具体的业务代码.
比如说:
- 我们可以将当前运行在 OpenResty 上的业务系统
- 一键迁移到 C 甚至于汇编代码上
- 而不会变动业务逻辑
- 甚至于将来迁移到新技术桟上, 也不用改变业务代码
- 只需要编写一个新的后端优化器
- 并添加到现有的 DSL 编译器中就好

此外, 我们也将获得全新的 web 应用框架:
- 编译型的
- 不再依赖一层层的嵌套, 从而令开发运行都越来越慢
我们必须同时实现美丽和效率:
这是未来商业产品级工程的必须特性
最好的语言就是 商业语言 正如春哥意识到的
基于商业语言开发,还有一个好处就是:
- 一但完成了一个 DSL
- 将一些业务逻辑放入后
- 如果有幸拿到客户原始需求文档
- 两厢对比,发现接近
- 就意味着作对了 ;-)
其实, 还有最好的方式来描述具体的领域问题:

是的, 只有机器真正理解你的业务逻辑, 那么:
- 可以获得比以往更多的嗯哼
- 比如自动生成测试用例
- 完成上下文分析
- 或者干脆为你即时生成真正可运行的实例
(是也乎:
这, 才是 OpenResty 真正的目标:
逼所有程序猿变成产品经理
)
TLog¶
- .5h 决定嗯哼
- 2.h 完成上篇
- 2.5h 完成下篇

Comments